AI-assisted literature screening: A hybrid approach using large language models and retrieval-augmented generation
Nov 30, 2025·, ,,,,,,,·
0 min read
,,,,,,,·
0 min read
Yiming Li
Xinsong Du
Yifei Wang
Xinyu Chen
Zhengyang Zhou
John Lian
Ya-Wen Chuang
Pengyu Hong
Peter C. Hou
Li Zhou
Abstract
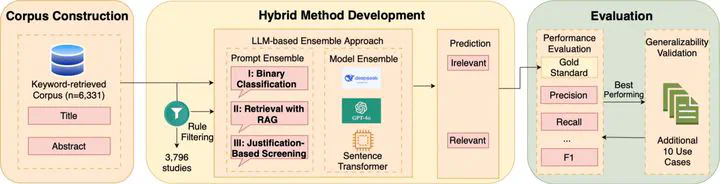
Objective: Current systematic literature reviews largely rely on manual screening of articles retrieved through keyword search, which is time-consuming and difficult to scale. To address this limitation, large language model (LLM)-based approaches offer the potential to automate the screening process. In this study, we aim to enhance the efficiency and accuracy of literature screening by developing an LLM-based method and exploring techniques such as rule-based preprocessing, prompt engineering (i.e., retrieval-augmented generation (RAG)) and ensemble strategies. Methods: We explored a hybrid framework that combines RAG prompting with LLM-based classification strategies. Our methods were developed and evaluated on a corpus of 6331 biomedical articles, focusing on identifying literature discussing the applications of LLMs in patient care using Electronic Health Record (EHR) data. We evaluated three recent models-DeepSeek-V3, Deepseek-R1 and GPT-4o under three prompting strategies: binary classification prompting, RAG prompting, and justification-based prompting. Given the context of literature screening, recall (sensitivity) was prioritized in this study to maximize the inclusion of relevant studies. Additionally, we also considered other metrics, including precision, specificity, and negative predictive value (NPV) to minimize the inclusion of irrelevant articles. To evaluate generalizability, the models and prompts were further tested on ten additional topics related to Cancer Immunotherapy and Targeted Therapy and LLMs in Medicine. Results: The hybrid approach combining rule-based preprocessing with DeepSeek R1 using RAG prompting (rule + DeepSeek-reasoner@Prompt II) achieved the best overall performance among individual models, with a precision of 0.34, recall of 0.77, NPV of 1.00, and g-mean of 0.87. Ensemble methods outperformed this approach greatly in precision, achieving a perfect score of 1.00 in the main use case, but showed comparable performance across other metrics, with the exception of F1. In generalizability tests, DeepSeek-R1 achieved the highest F1-score (0.93) and accuracy (0.88) across additional topics, whereas ensemble methods did not show substantial improvement. Conclusion: This study introduces a LLM-based approach that integrates RAG prompting and ensemble strategies to enhance literature screening, offering substantial gains in accuracy and scalability. The findings establish a foundation for advancing LLM-driven evidence synthesis in biomedical research and clinical decision support.
Type
Publication
International Journal of Medical Informatics